

MySQL
binlog、redolog和undolog的区别
binlog 主要用来对数据库进行数据备份、崩溃恢复和数据复制等操作,redolog 和 undolog主要用于事务管理,记录的是数据修改操作和回滚操作。redolog 用来做恢复,undolog 用来做回滚。
在 MySQL 中,redolog 和 undolog 只适用于 InnoDB 存储引擎,因为要支持事务。而不适用于 MyISAM 等其他存储引擎。而 binlog 则适用于所有存储引擎。
binlog 是 MySQL 用于记录数据库中的所有 DDL 语句和 DML 语句的一种二进制日志。他记录了所有数据库结构和数据的修改操作,如 INSERT、UPDATE 和 DELETE 等。
redolog 是 MySQL 用于实现崩溃恢复和数据持久性的一种机制。在事务进行过程中,MySQL 会将事务做了什么改动记录到 redolog 中。当系统崩溃或者发生异常情况时,MySQL 会利用 redolog 中的记录信息来进行恢复操作,将事务所做的修改持久化到磁盘中。
undolog 则用于在事务回滚或系统崩溃时撤销(回滚)事务所做的修改。当一个事务执行过程中,MySQL 会将事务修改前的数据记录到 undolog 中。如果事务需要回滚,则会从 undolog 中找到相应的记录来撤销事务所做的修改。另外,undolog 还支持 MVCC(多版本并发控制)机制,用于在发生并发事务执行时提供一定的隔离性。
脏读、不可重复读、幻读
脏读:读到了其他事务还没有提交的数据。
不可重复读:对某数据进行读取过程中,有其他事务对数据进行了修改(UPDATE、DELETE),导致第二次读取的结果不同。
幻读:事务在做范围查询过程中,有另外一个事务对范围内新增了记录(INSERT),导致范围查询的结果条数不一致。
隔离级别
JVM
什么是JVM ?
Java虚拟机(JVM, Java Virtual Machine)是Java编程语言的核心组件之一,它是一个抽象的计算机,为Java程序提供了一个运行环境。JVM的设计使得Java应用程序可以在任何安装了JVM的操作系统上运行,而无需考虑底层硬件和操作系统的差异,从而实现了“编写一次,到处运行”的理念。
为什么需要JVM ?
平台无关性:通过 JVM,Java 程序可以在不同平台上运行,只要该平台有对应的 JVM 实现。
安全性:JVM 提供了沙箱环境来限制程序对资源的访问,增加了安全性。
性能优化:JVM 内置了多种性能优化机制,如 JIT 编译、垃圾回收等,提高了程序的运行效率。
JVM的组成
类加载器
负责将
.class文件加载到内存中,并将其转换为方法区中的运行时数据结构。类加载器分为启动类加载器、扩展类加载器和应用程序加载器等。
运行时数据区
这些区域用于存储程序执行期间的各种数据。它们包括:
方法区:存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
堆:所有对象实例以及数组都在这里进行分配内存,它是垃圾回收的主要区域。
栈:每个线程创建的同时都会创建一个栈,用于存储局部变量表、操作数栈、动态链接、方法出口等信息。
程序计数器:记录当前线程所执行的字节码指令地址。
本地方法栈:与 Java 方法使用的 Java 栈类似,但它是为本地方法服务的。
执行引擎
解释或编译并执行字节码。执行引擎包括:
解释器:逐条读取字节码指令并解释执行。
即时编译器(JIT):将频繁使用的热点代码编译成机器码以提高性能。
垃圾收集器(GC):自动管理内存,回收不再使用的对象占用的空间。
本地接口
允许 JVM 调用操作系统特定的功能或库函数,如通过 JNI(Java Native Interface) 调用
C/C++编写的本地代码。
本地方法库
包含实现本地方法所需的库文件。
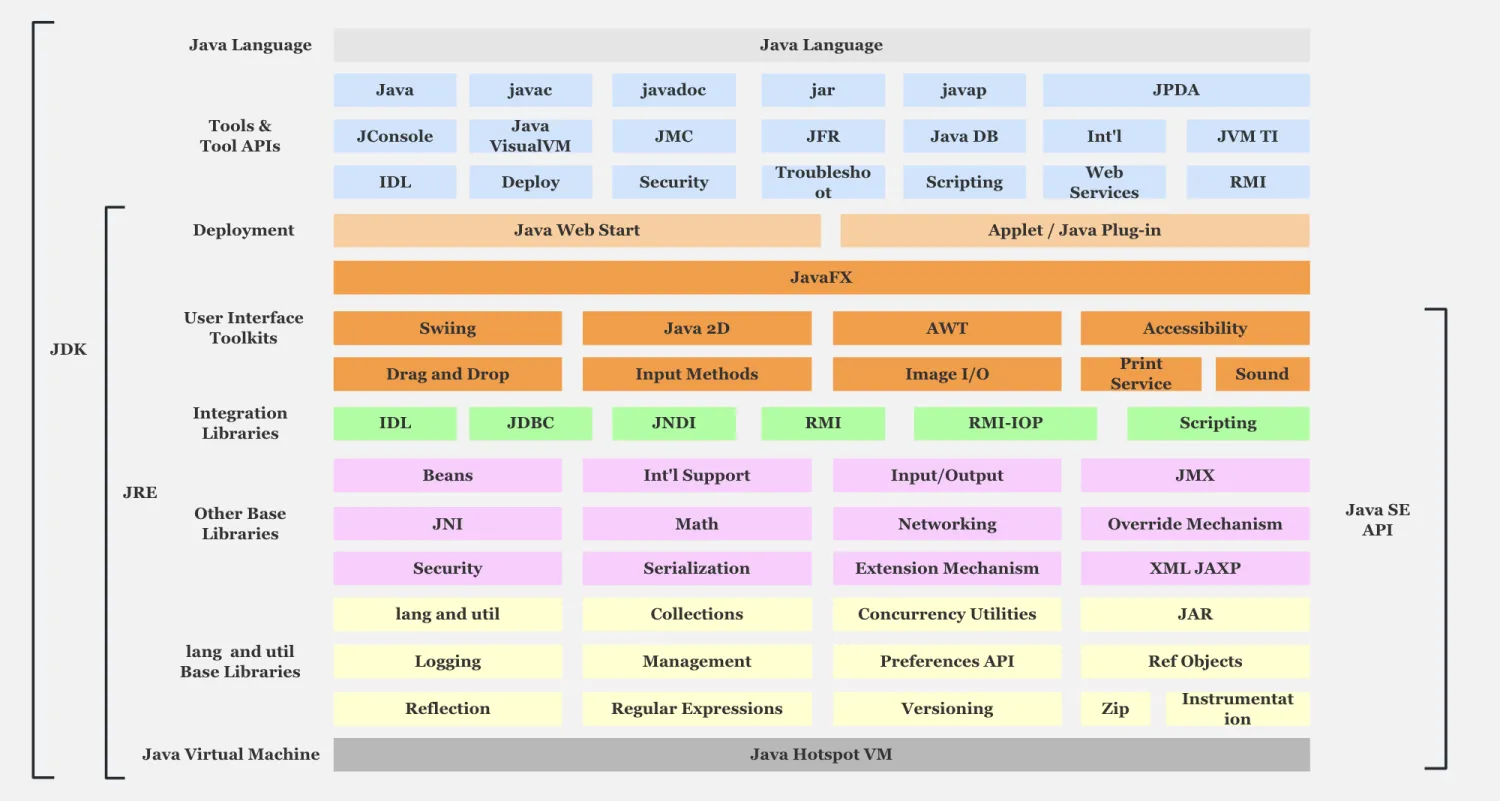
JVM的位置(在JRE中)
JVM的工作原理
加载阶段:类加载器将
.class文件加载到内存,并初始化类的数据结构。验证阶段:确保加载的字节码符合 JVM 规范,防止恶意代码破坏 JVM 的内部状态。
准备阶段:为类变量分配内存,并设置默认值。
解析阶段:将符号引用转换为直接引用。
初始化阶段:执行类构造器
<clinit>()方法,完成静态变量赋值和静态代码块执行。使用阶段:执行引擎开始执行程序逻辑,可能涉及解释执行、JIT 编译等。
卸载阶段:当某个类不再需要时,可以被垃圾收集器回收。