

JVM
对象实例化的过程
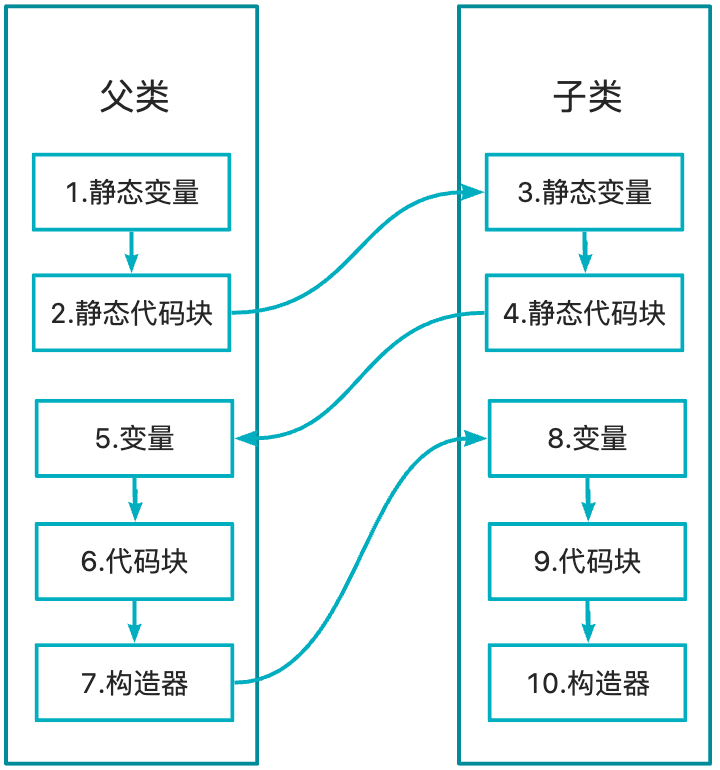
静态变量->静态代码块 -> 变量->代码块->构造器
具有父类的子类实例化过程
堆
在Java虚拟机(JVM)中,堆(Heap)是运行时数据区的一部分,用于存放对象实例和数组。它是所有线程共享的内存区域,主要用于动态分配内存给对象,并由垃圾回收器(Garbage Collector, GC)管理,以回收不再使用的对象所占用的空间。
线程共享:堆是被所有应用线程共享的一块内存区域。
对象存储:几乎所有的对象实例都在这里分配内存。注意,基本数据类型(如
int、char等)和对象引用通常存放在栈中,除非它们是在静态上下文中声明的或通过某些编译器优化机制(如逃逸分析)确定可以放置在堆上。垃圾回收:堆是垃圾收集器管理的主要区域。JVM使用不同的垃圾回收算法来自动管理和回收不再使用的对象,以避免内存泄漏并提高性能。
可扩展性:堆的大小是可以调整的,可以通过命令行参数(如
-Xms设置初始堆大小,-Xmx设置最大堆大小)来指定。根据应用程序的需求,JVM可以在最小值和最大值之间动态地调整堆的大小。
堆的分代模型
年轻代
包含了新创建的对象。它又被细分为三个部分:
Eden Space:大多数新实例化的对象都会在这里分配空间。
Survivor Space 0 和 Survivor Space 1:当Eden空间满了时,存活的对象会被移动到其中一个Survivor空间;每次Minor GC后,存活的对象会在两个Survivor空间之间来回移动,直到达到一定的年龄阈值。
老年代
存储经过多次Minor GC仍然存活下来的对象,或者是直接分配的大对象。这部分的垃圾回收频率相对较低,称为Major GC或Full GC。
永久代/元空间(逻辑上存在,物理上可能不在堆中)
在 JDK 8 之前,类的元数据(Class Metadata)、常量池、静态变量等信息存放在永久代(PermGen)。从JDK 8开始,这部分信息被移到了原生内存中的元空间(Metaspace),并且永久代被移除。这减少了由于永久代溢出而导致的应用程序崩溃的风险。
堆的调优命令和参数
-Xms 和 -Xmx:
-Xms:设置JVM启动时的初始堆大小-Xmx:设置JVM的最大堆大小。
-Xmn:
设置年轻代(Young Generation)的大小。年轻代是对象初次创建的地方,包括Eden区和两个Survivor区。
-XX:NewRatio:
设置老年代与年轻代的比例。例如,如果设置为2,则老年代是年轻代的两倍大。
-XX:SurvivorRatio:
设置Eden区与一个Survivor区的大小比例。例如,若设置为8,则Eden区是每个Survivor区的8倍大。
垃圾回收器选择:
-XX:+UseSerialGC: 选择串行垃圾收集器。-XX:+UseParallelGC: 选择并行垃圾收集器。-XX:+UseConcMarkSweepGC或-XX:+UseG1GC: 分别选择CMS垃圾收集器或G1垃圾收集器。
-XX:MaxGCPauseMillis:
设置垃圾回收的最大暂停时间目标,这将影响到GC的频率和类型。
-XX:GCTimeRatio:
设置垃圾回收占用的时间比例,即应用运行时间和垃圾回收时间的比率。
-XX:+PrintGCDetails 和 -XX:+PrintGCDateStamps:
打印详细的垃圾回收信息以及时间戳,有助于分析GC行为。
-XX:+HeapDumpOnOutOfMemoryError 和 -XX:HeapDumpPath=<path>:
在发生OutOfMemoryError时自动转储堆,并指定堆转储文件的位置。
-verbose:gc:
输出每次GC的信息,包括GC前后的堆使用情况和GC所花费的时间。
jstat:
Java统计监控工具,可以查看JVM的类加载、垃圾回收等统计数据。
jmap:
显示指定Java进程的内存映射或生成堆转储快照。
jstack:
用于打印Java进程的线程快照(线程堆栈跟踪)。
jcmd:
是一个多用途的命令行工具,它可以用来发送诊断命令给JVM,还可以用于触发GC、获取heap信息等。
-Xms1024m -Xmx1024m -XX:+PrintGCDetailsMySQL
UNION
UNION 是 SQL 中用于合并两个或多个 SELECT 语句结果集的关键字。它允许你将来自不同表或查询的数据行组合在一起,形成一个单一的结果集。
消除重复行
默认情况下,
UNION会自动去除结果集中重复的行(类似于DISTINCT操作)。如果你想保留所有匹配的行,可以使用UNION ALL。
列数和数据类型必须一致
参与
UNION的每个SELECT语句必须返回相同数量的列,并且相应位置上的列应该具有兼容的数据类型。
列名取自第一个 SELECT 语句
结果集中的列名总是采用第一个
SELECT语句中指定的列名。
不能对整个 UNION 结果排序
如果你想对最终的结果进行排序,需要在最后一个
SELECT语句后加上ORDER BY子句。注意,不能直接在UNION关键字之后紧跟ORDER BY。
支持子查询
UNION可以结合子查询一起使用,只要子查询的结果符合上述规则即可。